
What is Domain Logic?
All software has a domain in which it attempts to solve problems. This can be equivalent to a real-world business or to a field of engineering or math. The domain logic is the representation of the business rules of the domain being modeled. In object-oriented software engineering, a domain object model is used to model problem domain objects, or objects that have a direct counterpart in the problem domain. [1]Traditionally, domain logic in Ruby on Rails is modelled in ActiveRecord models. ActiveRecord is the default object-relational mapping (ORM) library for Rails. Hence, objects that represent domain logic are also responsible for persisting or saving data attributes to a relational database.
The Great Debate
There are two radically different schools of thought on combining domain logic with a persistence layer or ORM. First, we have Uncle Bob, one of the authors of the Agile Manifesto:
“The opportunity we miss when we structure our applications around Active Record is the opportunity to use object oriented design.” [2]
The context of that quote is about the confusion caused when you have objects that also happen to be data structures. Objects in object-oriented programming are diametrically opposed to data structures. Objects expose behavior while data structures have no behavior.Then, we have David Heinemeier Hansson–creator of Rails, proponent of opinionated software:
@dhh — It’s great to hear your comments on the latest memes in Rubyland/web dev. What are your thoughts on separating logic + persistence.
— Paul Campbell (@paulca) June 29, 2012
From this tweet we can see DHH’s opinion that a Rails application is a web app and nothing else. We shouldn’t be concerned about separating non-application specific business logic from our framework. We shouldn’t need to re-use our domain logic outside of Rails.So we have a dilemma. Should we follow Uncle Bob’s advice and isolate our domain logic from our database layer? Or should we keep on doing things the Rails way and use the active record pattern (which also happens to be named ActiveRecord) to both model behavior and persist data?
The Problem with Rails
In many cases, DHH is right. Our little pet-project blog app is nothing more than a blog. Its business logic is intimately tied to the delivery platform—the web. There is no need to separate out the domain logic. It’s just a simple CRUD app.But what happens when your app is more than just a blog? What if your application needs to model complex behavior—say, a payroll app. You have dozens of models and your tests start to take longer and longer with complex database interactions. Then you start wanting to separate out business logic by extracting domain objects. You mock or stub out your tests and they are moving fast again. But still, your views and controllers are tightly coupled with your models, reaching far inside to extract data. It can’t all be tested easily except by huge integration tests.If those problems sound all too familiar, you might be ready to re-discover some practices and approaches that have worked well in the history of software engineering.
The Solution: Object-Oriented Design
It just so happens that what’s needed to speed up our tests is the same things that are good for object-oriented software design. There are a handful of time-tested approaches that can make our applications faster, easier to maintain, and more bug-free. The first principle is single-responsibility. Each class should be responsible for a single concern. Put another way, classes should only have a single reason to change. If a class is responsible for too much it will require frequent changes and make the application more fragile.Rails’ models, which inherit from ActiveRecord::Base, are responsible for both domain logic and persistence. This is one responsibility too many. So the first step in refactoring a fragile Rails application is putting all domain logic in Plain Old Ruby Objects (POROs). Free from the constraints of the database we can now model our domain in a fully object-oriented way. We can use object-oriented design patterns such as inheritance, facades, decorators, and so on. For a full description of many such design patterns a good reference is Design Patterns: Elements of Reusable Object-Oriented Software.
Dependency Inversion
The next approach we will explore is creating a boundary that inverts the dependencies between controllers, views, and models. According to Uncle Bob’s Clean Architecture, software dependencies should all point towards higher-level business rules. The database, web, and other external interfaces thus become the lowest-level implementation details. This is the reverse of how Rails applications are often designed. Usually, the database design is considered first and then ActiveRecord models are created with a near one-to-one mapping to database tables. Clean architecture turns that process upside down and has you consider your domain logic far ahead of the database.Once you have a test-driven domain object model that begins to fully model and implement your business rules, you can begin to focus on the interfaces that control the boundaries between the web and the actual domain logic.
Use Cases
The interfaces that interact with the database, web, external services on the one side, and your domain entities on the other side, are called Use Cases. A use case can also be described as a User Story. A use case defines the interaction between a role and part of the system. There are special syntaxes for describing use cases, such as Cucumber steps. But in simple form a use case can be described in terms such as “a user logging in”, or “a manager adding a new employee”.In Rails, use cases can be implemented through Interactor models that take request objects passed in through the controller and return response objects that get rendered in the view. The request and response objects are simple data structures with no behavior or logic. Interactors can thus interact with controllers, domain objects, and repositories.
Repositories
At this point you may be thinking we’re throwing all of Rails out. But we’re not. In fact, we are going to keep on using ActiveRecord::Base as the base class for our repository models. The name repository implies a data store. So these repository models are responsible only for storing and retrieving data. We can use the full Active Record query interface if we want to, or drop down into plain SQL. It doesn’t matter how we implement repositories as long as our dependencies point away from them. With inverted depencies our application is loosely coupled and we can freely refactor domain logic without caring about the implementation details of the persistence layer.
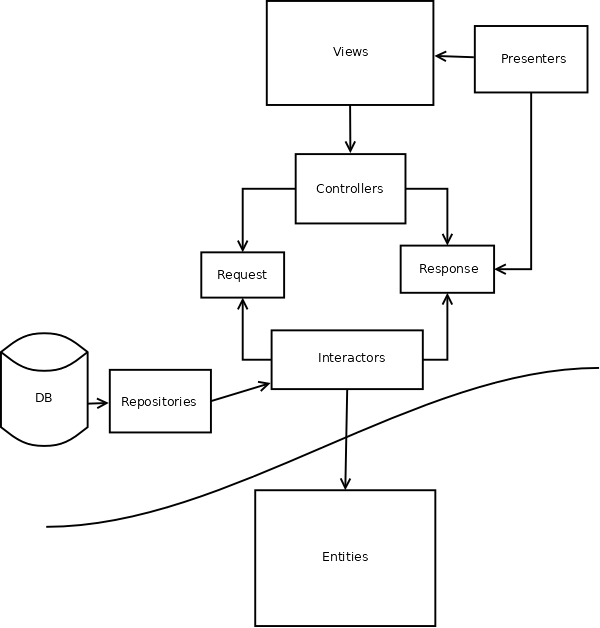
An Example in Rails
We tried this approach in a Rails app that had already been under development for a few months. The complexity of the domain led us to the decision to refactor away from the traditional Rails way towards this type of clean architecture. Immediately the benefits could be felt when running tests. The old tests were already taking about 30 seconds without too many cases. The new tests run in about a second and we can now freely add new ones without fear of slowing them down. Our domain logic was completely refactored from a database-centric one to a properly object-oriented one. This simplified the many table joins we had to do previously. Now we use object inheritance to group similar concepts and can get the behavior we need without complex database queries.
How it’s Done
First, I started off in a new clean directory and added a lib/ and spec/. Using test-first development, I started creating entities. Entities are where all the domain logic lives. They inherit from a base class called Entity.class Entity include ActiveModel::Validations attr_accessor :id def self.attr_accessor(*vars) @class_attributes ||= [:id] @class_attributes.concat vars super(*vars) end def self.class_attributes @class_attributes end def self.inherited(sublass) sublass.attr_accessor(*@class_attributes) end def initialize(attr = {}) attr.each do |name, value| send("#{name}=", value) end endend
I’m interested in the class and object attributes because it’s convenient for validations.Next, I implemented the Interactor base class.class Interactor attr_reader :request, :response def initialize(request = {}) @request = request @response = Response.new end private def save_repository(repo_class) if @request.params[:id] repo = repo_class.find(@request.params[:id]) repo.update_attributes(@request.object_attributes) else repo = repo_class.create(@request.object_attributes) end repo end def delete(repo_class) repo = repo_class.find(@request.params[:id]) repo.destroy endend
Notice there is a convenience method there used to save data into a repository. It can handle either create or update, depending on the params passed by the controller.What do the request and response objects look like?These have some behavior that make it easy to integrate Rails form helpers. For example, a response object that contains an id will be considered as a persisted record by a Rails form and so the form action will be the update url rather than the create url. They both are Hashie::Mash objects because that makes accessing attributes cleaner.Now how does this integrate with Rails? It’s simple. After I finished the basic domain object model and a couple of interactors, I dropped them into the Rails app directory. Be sure to add paths to entities and interactors in your autoload paths in config/application.rb. The application controller loads commonly used data attributes into every request:class ApplicationController < ActionController::Base before_filter :set_default_request def current_account_id @current_account_id ||= current_user.account_repository_id if user_signed_in? end helper_method :current_account_id protected def set_default_request if current_user @request = Request.new(current_user: current_user, current_account_id: current_account_id, params: params) else @request = Request.new(params: params) end endendYou’ll see there are still some ActiveRecord associations being used, partly in order to make Devise work. A user belongs to an account and both have their data stored in repositories. So what does a repository look like? Very simple, no logic:# == Schema Information## Table name: user_repository## id :integer not null, primary key# account_repository_id :integer# first_name :text# last_name :text# state :text# email :string(255) default(""), not null# encrypted_password :string(255) default(""), not null# reset_password_token :string(255)# reset_password_sent_at :datetime# remember_created_at :datetime# sign_in_count :integer default(0), not null# current_sign_in_at :datetime# last_sign_in_at :datetime# current_sign_in_ip :string(255)# last_sign_in_ip :string(255)#class UserRepository < ActiveRecord::Base self.table_name = 'user_repository' belongs_to :account, class_name: 'AccountRepository', foreign_key: :account_repository_id devise :database_authenticatable, :registerable, :recoverable, :rememberable, :trackableendNow controllers simply route traffic and call interactors to perform the actual use cases:class UsersController < ApplicationController respond_to :html before_filter :authenticate_user! def user_params params.require(:user).permit :first_name, :last_name, :email, :password, :password_confirmation, :phone end private :user_params def index @response = BrowseUsers.new(@request).call.extend(UserPresenter) respond_with @response end def show @response = LoadUser.new(@request).call respond_with @response end alias_method :edit, :show def new @response = NewUser.new(@request).call respond_with @response end def create @request.object_attributes = user_params @response = SaveUser.new(@request).call respond_with @response.user, location: users_path end alias_method :update, :create def destroy @response = DeleteUser.new(@request).call respond_with @response, location: users_path endend
We make use of presenters to handle presentation details as well. The call method on an interactor instance always takes a @request object and returns a @response object which can be a nested data object. The views only know about what’s in @response. It is the interactor’s duty to get the data required for the view from the repository. Views know nothing about ActiveRecord, entities, or the database. Repositories know nothing about business rules or domain logic.Finally, here’s a set of interactors that can handle simple CRUD operations:class LoadLocation < Interactor def call @response.location = location.attributes @response end def location LocationRepository.joins(:manager) .select("*, user_repository.name AS manager_name") .where(account_repository_id: @request.current_account_id) .find(@request.params[:id]) endendclass LoadLocations < Interactor def call @response.locations = locations @response end def locations LocationRepository.joins(:manager) .select("*, user_repository.name AS manager_name") .where(account_repository_id: @request.current_account_id) .map(&:attributes) endendclass SaveLocation < Interactor def call location = Location.new(@request.object_attributes) if location.valid? repo = save_repository(LocationRepository) @response.location = repo.attributes else @response.location = @request.object_attributes @response.location.errors = location.errors end @response endendclass DeleteLocation < Interactor def call @response = delete(LocationRepository) endend
Conclusion
This is a very different way of doing things as far as Rails goes. It offers a clean boundary between application logic and implementation details. It would be quite easy to refactor an app like this into a Sinatra app. Or it could even use a different language for the delivery mechanism. External services should be easy to plugin. Likewise for database backends and ORMs. But most importantly, implementing a Rails app using a clean architecture reminds us to keep up the red-green-refactor TDD cycle and to make sure our models only have a single responsibility. Yes, it is more work this way but this is a case of not being penny wise and pound foolish. We can build seemingly powerful applications very quickly in Rails. But if we want to keep maintaining and refactoring and adding features for years, that initial productivity boost that Rails affords us will quickly run out and leave us with a big ball of mud.Comment below with your thoughts.Cover image by Alan Levine

